
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 디미터법칙
- Java
- Alexnet
- 1107번
- MachineLearning
- GPT
- 딥러닝
- cs231n
- deeplearning
- 알고리즘
- 논문
- 3745
- 클린코드
- 다익스트라
- 백준9095
- 백준
- NLP
- 논문리뷰
- 알렉스넷
- 머신러닝
- 관심사분리
- 1261
- 논문구현
- dijkstra
- 자바
- 백준 1339
- 백준 1916 자바
- 짝지어제거하기
- 1916
- 백준 1339 자바
- Today
- Total
산 넘어 산 개발일지
[CS231n - Lecture 6] Training Neural Networks - Part I-2 본문
[CS231n - Lecture 6] Training Neural Networks - Part I-2
Mountain96 2021. 8. 2. 15:21Weight Initialization(가중치 초기화)
방법 1. 모두 0으로 초기화
이 경우 W가 모두 같으므로, 모든 뉴런이 같은 일만 하게 되는 문제점이 있다.
또한 모든 W가 모두 같기 때문에 업데이트도 항상 같은 값으로 업데이트된다.
방법 2. 작은 수로 초기화

이런 식으로 무작위으 작은 수로 초기화하는 방법도 생각해볼 수 있다. 그러나 이경우 얕은 네트워크에서는 작동하지만, 네트워크가 깊어질수록 작동하지 않는다.
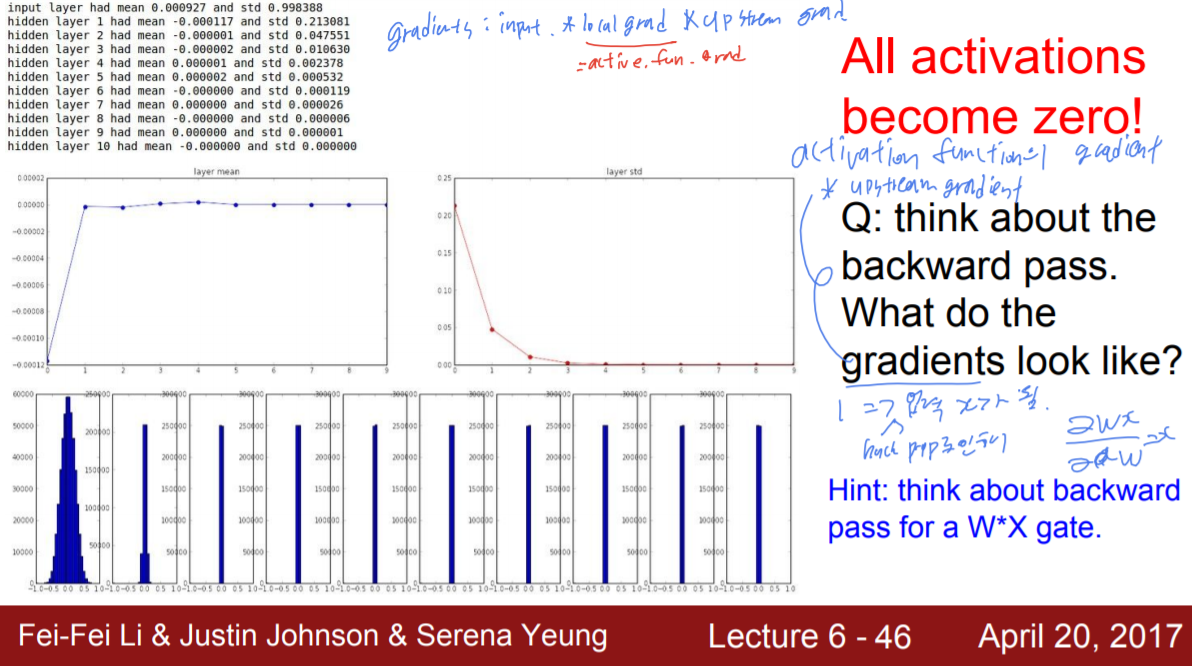
정상적으로 작동하지 않는 첫 번째 이유는, 모든 W가 작기 때문에 layer가 거듭될수록 출력되는 activation 이 점점 작아지기 때문이다. 이는 곧 0으로 수렴하게 된다.
두 번째 이유는 역전파에 있다. 역전파 시 계산하는 Gradient는 위에서 내려온 미분값 * 현재 미분 이다. 이 때 현재 식은 W*X인 상태에서 W를 업데이트하기 위해 W에 대한 미분을 하면 X만 남게 된다. 이 때 X는 0에 가까운 값이므로 Gradient는 계속해서 0에 가까워지기만 하는 것이다.
방법 3. Xavier initialization
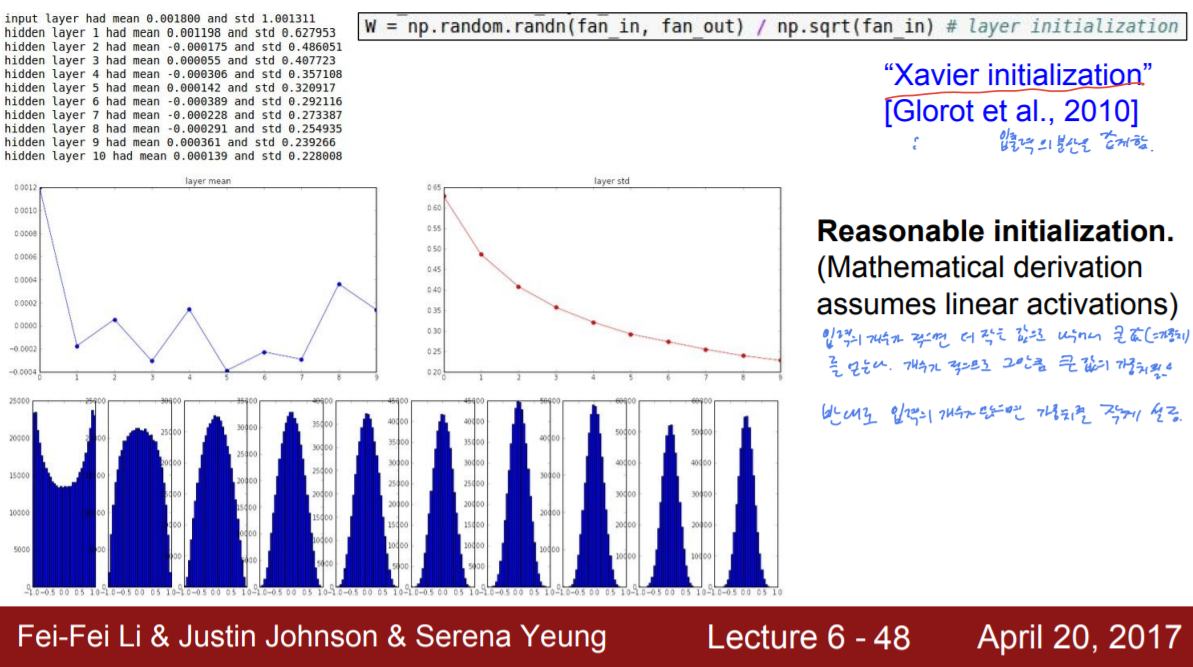
Xaiver Initialization은 식에서 보이는 것처럼, 입력의 개수가 적을수록 더 작은 값으로 가중치를 나누어준다. 그렇기 때문에 입력이 적으면 가중치는 반대로 큰 값을 갖게 되는 것이다. 이는 입력 개수가 적으면 가중치 값을 크게 하여 한 가중치 값의 영향력을 늘려주고, 반대로 입력의 개수가 많으면 그 영향력을 분산한다고 볼 수 있다.
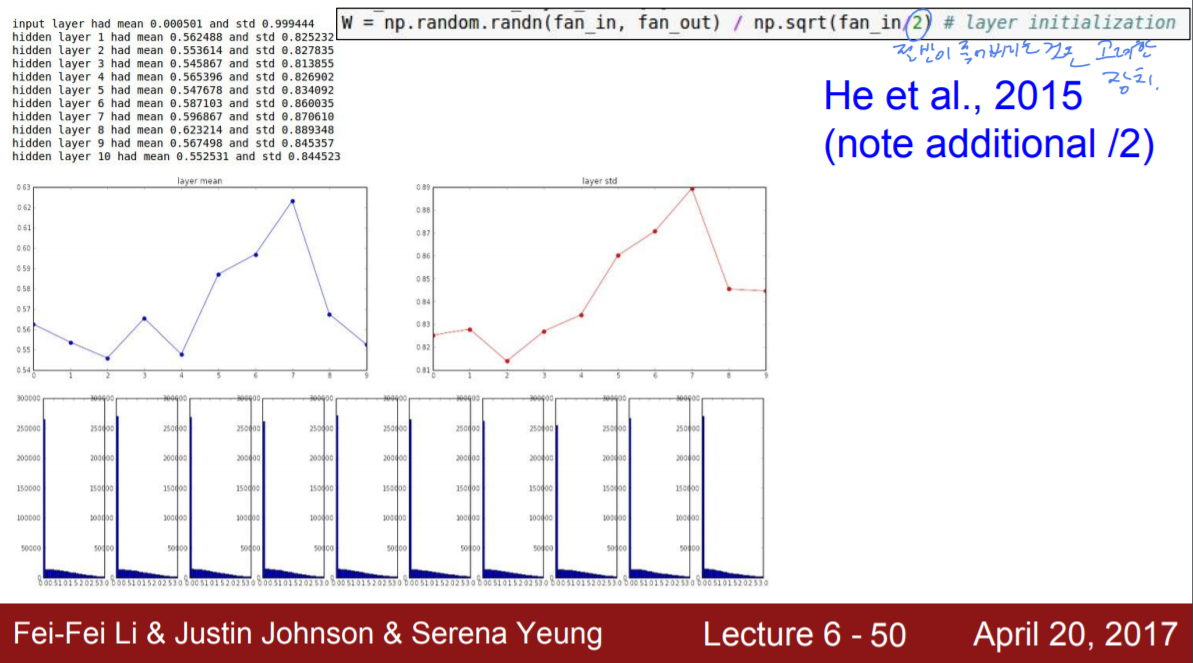
다만 ReLU의 경우, 이론상 출력의 반이 0으로 죽어버리므로, 이를 보완하기 위하여 마지막 나누는 부분에 /2를 더해준다.
Batch Normalization

출력된 결과값 모두가 한 가우시안 분포 안에 존재하도록 값을 조정한다. 이는 각 차원별로 평균과 분산을 구한 뒤, 이를 Normalize(Standardization)해줌으로써 가우시안 분포로 만들 수 있다.

이러럼 보통 FC Layer나 Convolution Layer 다음에 Batch Normalization이 온다. 다만, 앞서 언급한 것처럼 Batch Normalization은 일반적으로 Feature 단위로 normalize하지만, Convlution Layer에 적용할 때는 channel 단위로 normalize해준다.
또한, Batch Normalization은 데이터들을 Linear 안에 분포하게 만는 과정이므로, FC layer 와 Convolution layer 외에도 nonlinear 앞에서 쓰인다.
그러나, 이를 tanh에 쓸 때는 문제가 있다. tanh에 Batch Normalization을 사용함으로써 tanh에서 데이터들이 linear한 부분에만 분포하도록 강제할 수 있다. 그러나 이렇게 되면 saturation되는 부분이 완전히 사라지게 되는데, 이를 0% Saturation이 아니라 임의의 %만큼 Saturation을 하도록 허용할 수는 없을까?

일정한 양의 saturation을 허용하기 위해 위와 같은 식이 나왔다. 먼저 일반 Batch Normalization을 사용하여 x를 구한다. 그 뒤, x에 r을 곱하고 B를 더해주어 변화를 주는 것이다. 이 때, 이 r과 B는 사용자가 임의로 정할 수 있는데, 이를 통해 얼만큼의 saturation을 허용할지를 정할 수 있다. 만약 r=표준편차, B=평균 으로 설정하면 원래의 Batch Normalization 식으로 돌아가므로 Saturation=0%로 허용하겠다는 의미가 된다.
Babysitting the Learing Process
1. Preprocess Data
데이터를 zero-centered, normalize해준다(image의 경우 normalize 필요 x)
2. Choose the architecture
네트워크 구조를 선택한다.
input image의 사이즈, hidden layer 개수, hidden neuron 개수, output neuron 개수 등등을 설정한다.
3. Loss가 합당한지 체크한다.

앞서 배운 Multiclass SVM Loss, Softmax classifier 등의 디버깅 전략을 활용한다.
우선 regularization은 해제해주고, 그 상태로 loss를 계산해준다.
SVM loss의 경우 초기 loss = (class 수) - 1 이어야 하고
Softmax의 경우 초기 loss= -log(1/class수) 여야 한다.
이후, regularization을 적용하여 loss가 조금 올라가는지 확인한다. loss가 올라가야 정상이다.
4. 본격적인 학습

학습 초반에는 데이터의 일부만 학습을 시켜본다. 이 일부 학습을 통해 모델이 올바른지를 보는 것이다.
데이터가 많지 않으므로 loss가 낮고 overfit될 가능성이 높다. 또한 regulaization을 적용하지 않은 상태에서 loss가 내려가는지 확인하는 것도 좋다.
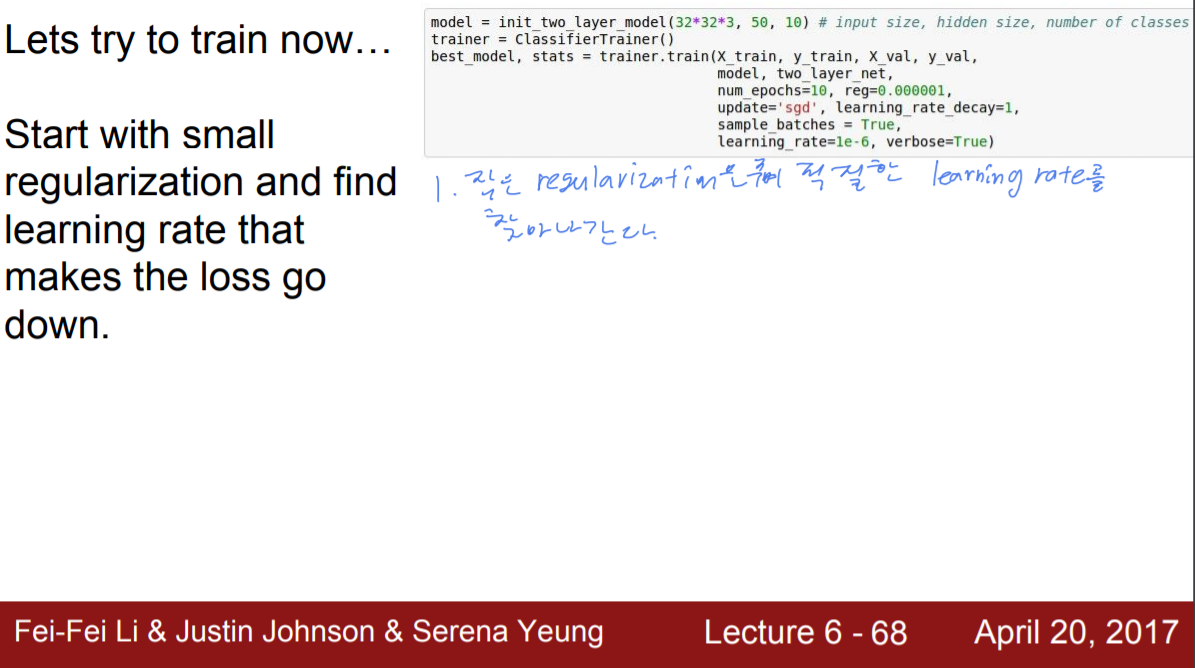
이후, regularization을 적용한 뒤 계속해서 학습해본다. regularization은 적은 수로 적용하여, 적절한 learing rate를 찾아가는 것이다. 이 때 나타날 수 있는 시나리오는 다음과 같다.
- loss가 내려가지 않는다 : learning rate가 너무 낮다.
- loss가 엄청 튄다(급증한다. ex NaN) : learning rate가 너무 크다.
보통은 1e-3 ~ 1e-5의 learning rate로 시작하는 것이 바람직하다.
Hyperparameter Optimization
Cross-validation strategy
초반에는 적은 epoch(1~5)만큼만 시도해보면서 대략적으로 파라미터가 어떻게 작동하는지를 살펴본다(넓은 범위)
이후 조금씩 좁게 들어가면서 파라미터를 수정한다(finer search) (좁은 범위)

예를 들어, 위와 같이 몇 에포크를 돌려보고는, fine search를 할 만한 부분들을 골라낸다. 골라내는 기준은 validation_accuracy의 수치이다.

finer search에서는 조금씩 lr과 reg의 범위를 좁혀가며 epoch을 돌려본다. 그러나 lr(learning rate)이 한 쪽에만 몰리면 그 부분만 집중적으로 탐색하게 되므로 꼭 좋은 결과라고는 할 수 없다.

finer search에는 보통 2가지, Random search와 Grid search가 있는데 일반적으로 Random Search가 더 좋다. 왜냐하면 Random Search는 여러 방면으로 시도해볼 수 있는 기회가 생기는 반면 Grid search는 고정되어 있기 때문에 정답쪽의 방향이 있음에도 적은 횟수만 시도가 가능하다.

이 외에도, 설정할 수 있는 하이퍼파라미터에는 네트워크 구조, leraning rate, decay schedule(Learning rate 감소 기법), uddate type, regularization 등이 있다.
출처 : https://www.youtube.com/c/stanfordengineering/featured
Stanford University School of Engineering
The Stanford School of Engineering has been at the forefront of innovation for nearly a century, creating pivotal technologies that have transformed the worlds of information technology, communications, medicine, energy, business and beyond. The faculty, s
www.youtube.com
'머신러닝&딥러닝 > cs231n' 카테고리의 다른 글
| [CS231n - Lecture 7] Training Neural Networks - Part II (0) | 2021.08.11 |
|---|---|
| [CS231n - Lecture 6] Training Neural Networks - Part I (0) | 2021.07.30 |
| [CS231n - Lecture 5] Convolutional Neural Network (0) | 2021.07.28 |
| [CS231n - Lecture 4] Backpropagation and Neural Networks (0) | 2021.07.27 |
| [CS231n - Lecture 3] Loss Functions and Optimization (0) | 2021.07.14 |



