
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 1107번
- 논문구현
- 관심사분리
- 백준
- 디미터법칙
- Alexnet
- 백준9095
- 논문
- 다익스트라
- Java
- deeplearning
- 자바
- dijkstra
- 1261
- 백준 1339
- 논문리뷰
- 짝지어제거하기
- cs231n
- 알렉스넷
- 백준 1916 자바
- 알고리즘
- 머신러닝
- 1916
- 3745
- 클린코드
- 딥러닝
- NLP
- MachineLearning
- GPT
- 백준 1339 자바
- Today
- Total
산 넘어 산 개발일지
[논문 리뷰] GPT-1 리뷰 본문
1. 배경

당시 Unlabeled dataset은 6백만개가 넘는 글과 35억개가 넘는 단어들로 넘쳐났지만, Labeled dataset은 너무나 부족한 상황이었다. 따라서 Unlabeled dataset으로 의미 있는 언어 정보를 학습하는 모델이 필요했다.
Unlabeled dataset으로 언어 정보를 학습한 모델의 장점
- 시간 비용이 많이 드는 추가적인 labeling작업을 대체하여 학습에 사용할 수 있음.
- 지도학습 하기에 충분한 데이터셋이 있다면, unlabeled dataset에서 학습한 정보들로 성능을 향상시킬 수 있음.
또한, 당시 많은 연구들에서 word embedding과 같은 단어 레벨의 정보를 사용하여 성능 향상을 보였다는 것이 많았다. 그러나 저자들은 이보다 더 높은 레벨의 정보들을 얻고자 하였다. (Phrase-level 혹은 sentence-level embedding)
unlabeled data로부터 단순히 단어 레벨의 정보를 넘어서 더 많은 정보를 얻는 것은 다음 두 가지 이유에서 어려운 점이 있다. (단어 레벨
- 어떤 목적함수가 가장 효과적인지를 모름.
- target task에 전이학습을 할 때 어떤 방법이 가장 좋은지에 대한 공식적인 합의가 아직 없음.
물론 당시에도 전이학습에 관한 개념이 있었지만, 대체로 복잡한 방법들을 통해 기존 모델 구조를 뒤바꾸는 형태로 학습이 이루어졌다.
따라서 논문 저자들은 unlabeled dataset에서 학습한 언어 모델을 만들고, 이 언어 모델과 labeled dataset을 사용해 모델 구조의 변환을 최소화하면서 전이학습을 하고자 하였다.
1-1. Generative VS Discriminative
Discriminative
데이터 X가 주어졌을 때 Y로 분류될 조건부확률
Generative
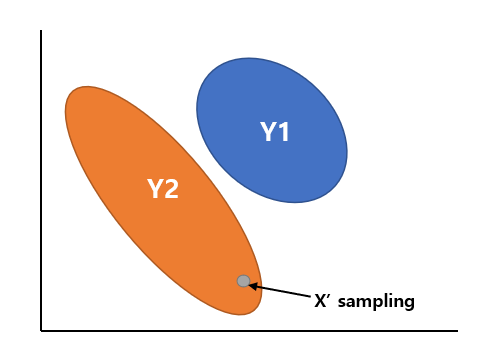
데이터 X의 분류를 학습하기보다는 분포를 학습하는 개념이다.
2. 학습 방식
2-1. Transformer Block
Attention is All you need에서 나온 Transformer와는 다르게, GPT에서는 Transformer의 Decoder만 사용했으며 Decoder 구조에도 차이가 있다.
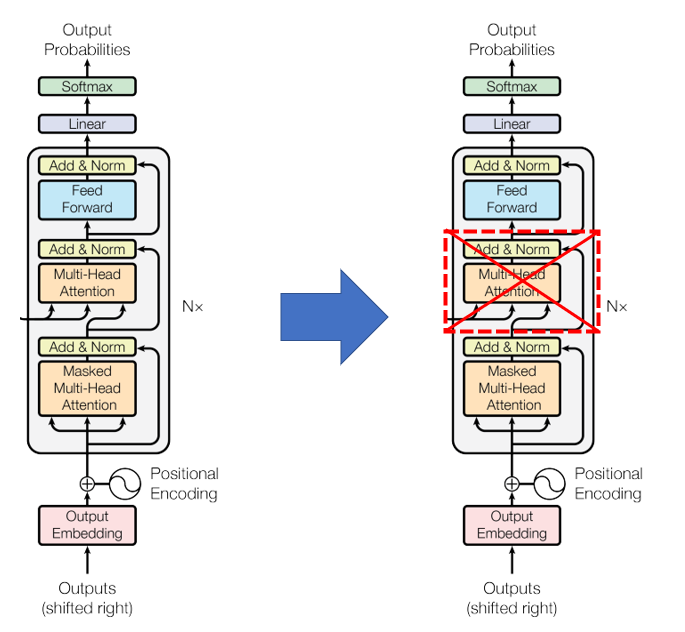
기존 Transformer decoder의 구조에는 Masked Attention과 Encoder에서 정보를 받아서 attention을 수행하는 encoder-decoder attention이 있었지만 이 부분이 사라졌다. 따라서 GPT-1에서 사용하는 Transformer block은 다음과 같다.
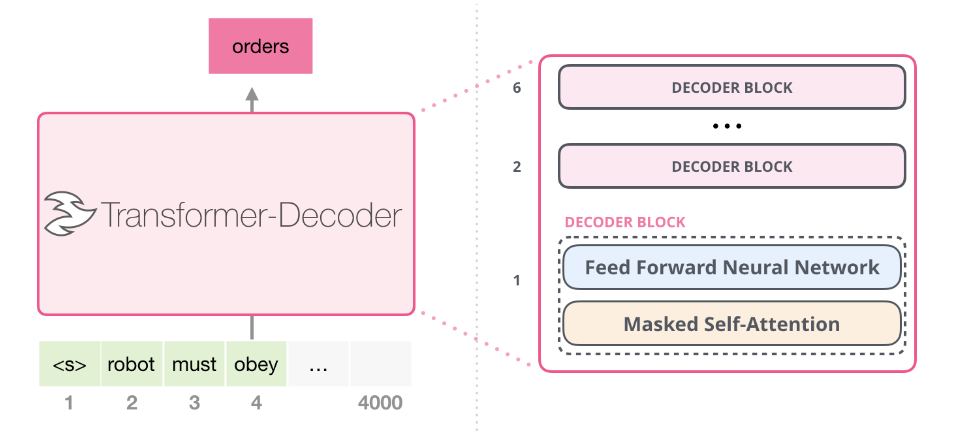
(이미지 출처 : Jay Alammar https://jalammar.github.io/illustrated-gpt2/)
GPT-1에서는 위 그림과 같은 디코더 블록을 12개 쌓아서 transformer_block을 만들었다.
GPT-1은 목적함수로 우도(likelihood)를 최대화하는 방법으로 모델을 학습한다.
2-2. Unsupervised pre-training
pre-training의 목적은 파라미터들의 좋은 initial 값 찾기이다. 또한, 사전학습을 사용한 모델은 사전학습 없이 직접 task에 특화된 모델보다 일반화 성능이 우수한데, 이는 사전학습이 Regulaization처럼 작용하기 때문이다.
ELMO와의 비교
ELMO는 GPT 이전에 성공적이었던 언어 모델 중 하나이다.
| ELMO | GPT-1 | |
| 구조 | LSTM | Transformer Decoder |
| 방향 | 양방향(Bi-Directional) | 단방향(Forward) + masking |
GPT-1에서는 LSTM이 아닌 Transformer의 디코더를 사용함으로써 긴 범위의 언어 정보를 사용할 수 있게 함으로써 Long term dependency를 해결하였고 다양한 Task에서도 더욱 좋은 성능을 보여주었다.
unsupervised pre-training은 위
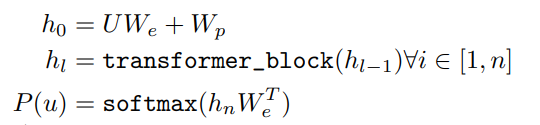
즉 U가 입력으로 들어오면
2-3. Supervised fine-tuning
unsupervised pre-training이 끝난 뒤 task에 맞는 지도 학습을 진행하며, 학습 과정에서 기존에 구한 parameter들을 해당 task에 맞게 업데이트하게된다. fine-tuning을 위한 목적함수는
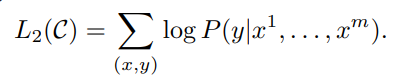
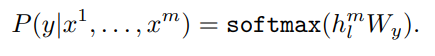
즉 이전에 학습한 사전학습 모델에
따라서 전이학습을 위해 모델에 여러 복잡한 작업을 가했던 과거 연구들과는 달리, GPT에서는
Auxiliary training objectives(보조학습목적함수)
이때 데이터셋
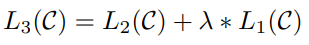
따라서 supervised fine-tuning시 최적화해야 할 목적함수는
2-4. Input transformation(traversal-style approach)
GPT는 연속된 시퀀스 데이터들로 학습되었지만, task마다 input이 구조적인 특징을 지니는 경우도 있다. 가령 QA의 경우 context document와 question, 그리고 answer가 필요하다. 기존 연구들에서는 이런 task를 위해 input을 변형하기보다는 사전학습 모델 위에 여러 복잡한 구조를 쌓았다. 그러나 GPT에서는 input에 토큰들을 추가하고 모델의 출력값에 다양한 연산을 추가하여 이를 해결하였다.
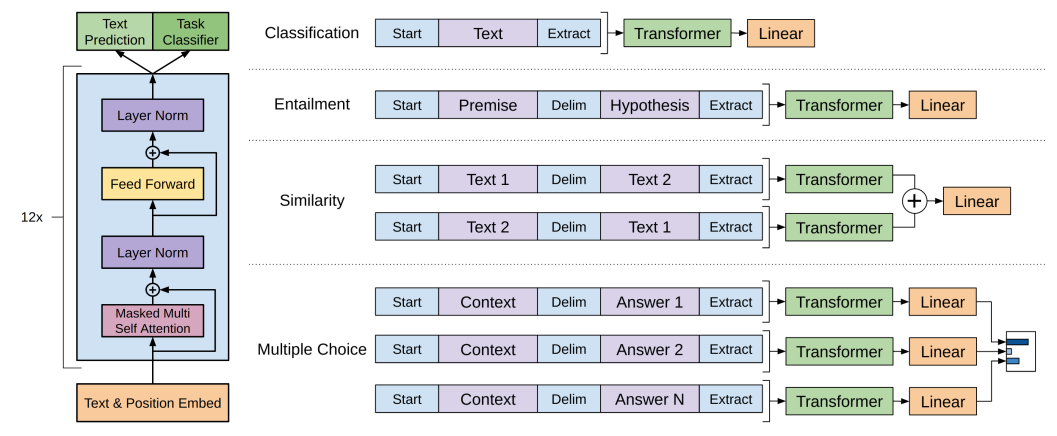
공통
- 모든 입력의 시작과 끝에는 <s>, <e> 토큰을 추가하여 시퀀스의 시작과 끝을 알린다.
- delimiter token으로 $을 쓴다. 보통 문장을 구분할 때 사용된다.
Textual Entailment(Natural Language Inference)
두 문장이 주어졌을 때 두 문장간의 관계를 분류하는 task이다.
한 문장이 다른 문장을 수반하는지(동일한 의미인지)(entailment), 두 문장이 모순되는지(contradiction), 아니면 아무 관계도 없는지(neutral)에 대해 분류한다.
두 문장 중 한 문장을 premise(전제)
Semantic Similarity
두 문장의 의미가 유사한지를 분류하는 작업이다. 예를 들어 "나는 인셉션 영화를 제일 좋아한다" 라는 문장과 "내가 가장 재미있게 본 영화는 인셉션이다" 라는 문장은 유사한 문장이다.
유사한 문장 간에는 어떤 문장이 먼저 오든지 상관없이 결과값이 일정하므로 문장의 순서가 결과에 무관하다. 따라서 문장 A, B가 오는 상황과 B, A가 오는 상황 모두에 대해 학습을 진행한다. 이를 위해서 두 개의 input을 준비한다.
- input1 :
- input2 :
이후 transformer를 거친 뒤의 출력을
QA
QA에서는 데이터가 context document
- input 1 :
- input 2 :
- input n :
이렇게 n개의 input이 각각 독립적으로 transformer에 입력되고 linear layer까지 수행된다. 이후 linear layer에서 출력된 n개의 output에 softmax를 적용하여 확률분포로 만든다.
3. 분석
3-1. layer 개수에 따른 변화
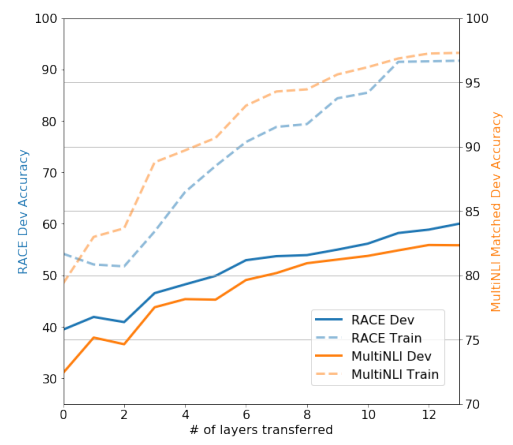
사전학습 모델에 사용된 layer 개수(transformer block 개수인 듯 하다)에 따라 모델의 성능을 관찰한 결과이다. RACE, MultiNLI 데이터셋에서 모두 layer가 늘어남에 따라 정확도가 높아짐을 확인할 수 있고, 12개의 layer부터는 크게 성능이 좋아지지 않고 수렴했다.
3-2. fine tuning의 update를 점진적으로 진행했을 때의 결과
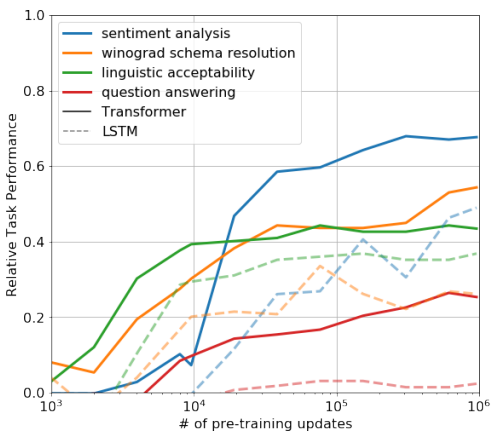
비지도 사전학습으로 모델을 만든 뒤, 각 task에 대해 fine-tuning을 했을 때 파라미터들을 점진적으로 업데이트함에 따라 나타나는 성능을 보여준다. 일반적으로 많이 업데이트할 수록 성능이 높아진다.
이에 대해 어떤 분들은 "zero-shot VS fine-tuning을 비교하여 fine-tuning의 우수함을 보여주는 자료다" 라고 하시고, 어떤 분들은 "LSTM과 비교했을 때 우수한 성능을 보여주는 자료다"라고도 하시는데, 어떤 것이 맞는지는 잘 모르겠다.
참조
'논문 리뷰 > NLP' 카테고리의 다른 글
| [논문 리뷰] Sequence to Sequence Learning with Neural Networks 요약 및 리뷰 (0) | 2022.07.02 |
|---|---|
| [논문 리뷰] GPT-1 : Improving Language Understanding by Generative Pre-Training (OpenAI) (2) | 2022.03.06 |

