
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 1261
- 백준 1916 자바
- 알렉스넷
- 디미터법칙
- dijkstra
- 클린코드
- GPT
- 짝지어제거하기
- 딥러닝
- Java
- 알고리즘
- 관심사분리
- 백준9095
- 다익스트라
- MachineLearning
- 논문구현
- 3745
- 백준 1339
- deeplearning
- 1107번
- cs231n
- 논문리뷰
- 머신러닝
- 백준
- 논문
- 백준 1339 자바
- NLP
- 자바
- 1916
- Alexnet
- Today
- Total
산 넘어 산 개발일지
[논문 리뷰] Sequence to Sequence Learning with Neural Networks 요약 및 리뷰 본문
[논문 리뷰] Sequence to Sequence Learning with Neural Networks 요약 및 리뷰
Mountain96 2022. 7. 2. 16:10서론
이번 논문은 기존 SMT에서 부분적으로만 활용되었던 DNN을 본격적으로 활용하여 BLEU 점수에서 이를 뛰어넘거나 비슷한 점수를 기록했다는 점에서 의미가 있다. 그리고 기존 NLP에서는 Input으로 고정된 길이의 벡터를 넘겨줘야만 했는데, 가변 길이의 벡터를 사용할 수 있게 했다는 점도 큰 발전이었다. 어떻게 가변 길이 벡터를 사용할 수 있었고, 어떤 방식으로 훈련을 했는지 위주로 리뷰를 해볼 것이다.
본론
1. RNN vs LSTM
RNN은 긴 데이터에 대해서는 기울기 소실 문제로 인해 약한 모습을 보인다. 반면 LSTM은 RNN보다는 긴 데이터에 더 강인한 성능을 보인다. 물론 다른 여러 논문들에서 LSTM 역시 긴 데이터에 약하다는 것을 언급한다. 그러나 본 논문에서는 LSTM을 사용하여 긴 문장의 데이터에 대해서도 높은 성능을 발휘했다.
2. Sentence Reverse
LSTM 자체가 어느 정도의 긴 문장에도 적용 가능하여 성능이 좋았겠지만, 높은 성능을 발휘할 수 있었던 또 다른 이유는 입력 시퀀스의 순서를 거꾸로 했기 때문이다. 예를 들어 ['a', 'b', 'c']를 입력으로 받고, target은 ['A', 'B', 'C']라고 해보자. 입력과 target을 이어붙인다고 했을 때, 입력 단어와 매핑되는 target 단어 사이의 거리는 모든 입력에 대해 3으로 동일하다. 이때의 거리들의 평균은 3이고, 최소 거리는 3이 되는데, 이 최소 거리가 minimal time lag가 된다.

이제 입력의 순서를 바꿔보자. ['a', 'b', 'c'] 대신 ['c', 'b', 'a']를 입력하면 거리가 늘어나는 단어와 줄어드는 단어가 모두 생길 것이다. 그러나 거리의 평균은 3으로 변함이 없으며, 대신 최소 거리가 1로 줄어든다.

논문 저자들은 이같은 최소 거리의 감소가 minimal time lag를 의미하고, 이로 인해 역전파를 할 때 입력 단어와 target 단어 사이의 "관계 형성(establishing communication)" 이 쉬워져서 결국 전체적인 성능 증가로 이어진다고 설명한다. 실제로 입력을 inverse 했을 때는 안했을 때와 비교하여 test perplexity가 5.8에서 4.7로 줄어들었고, BLEU 점수도 25.9에서 30.6으로 증가했다.
3. 고정 길이 벡터 VS 가변 길이 벡터
당시의 DNN은 inputs과 targets이 고정된 차원으로 인코딩된 벡터를 사용해야만 했다. 그러나 현실 세계에서는 다양한 길이의 시퀀스들이 존재하므로 이를 적용하는 것에는 한계가 있었다. 따라서 적용하려는 도메인과는 별개로 Sequence to Sequence로 매핑하는 것을 학습하는 것이 중요하다고 할 수 있다.
가변 길이의 벡터를 사용하기 위해 논문은 LSTM 하나를 사용하여 입력 시퀀스를 입력으로 받고 고정된 차원의 벡터를 출력한다. 그리고 또 하나의 LSTM을 사용하는데, 이는 이전 LSTM에서 출력된 벡터를 입력으로 받아 출력 시퀀스를 생성한다. 여기서 입력으로 사용된다는 말은 두 번째 LSTM의 초기 hidden state로 사용된다는 것을 의미한다.
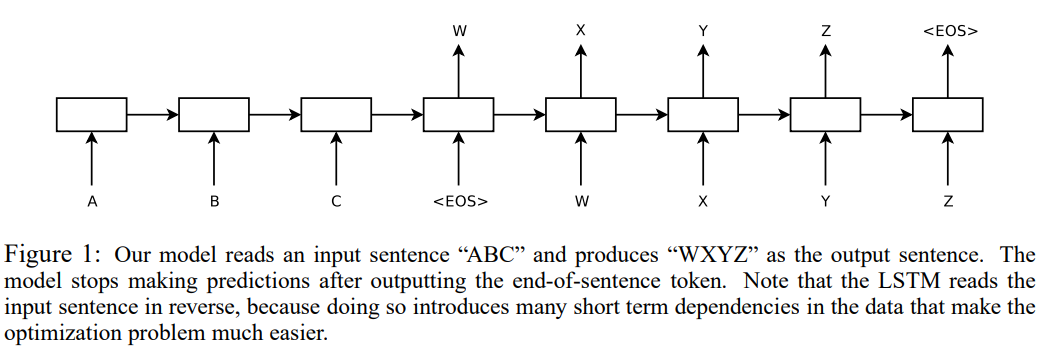
위 그림에서는 [A, B, C]를 입력 시퀀스로 받고 첫 번째 LSTM을 거친다. 모든 데이터의 끝에는 <EOS>로 되어 있다. LSTM이 <EOS>를 입력받고 난 뒤의 벡터가 두 번째 LSTM에 들어가며, 이 벡터가 곧 convext vector가 된다. 두 번째 LSTM에서는 앞서 언급한 것처럼 W를 입력으로 받고 앞서 출력된 context vector를 initial hidden state로 사용한다.
4. Model

LSTM은 조건부 확률 p(y_1, y_2, ..., y_T' | x_1, x_2, ..., x_T)를 계산하게 된다. 이때 입력 시퀀스의 길이 T와 출력 시퀀스의 길이 T'는 다를 수 있음에 유의하자. 이를 계산하기 위해 우선은 첫 번째 LSTM에서 고정된 길이의 context vector v를 계산하고 LSTM_LM formula를 사용하여 y들을 계산한다. initial hidden state은 v로 설정된다. 각 확률분포 p는 모든 단어들에 대한 softmax를 적용하여 표현된다.

모델은 위와 같이 log 확률(log likelihood)를 최대하하는 방식으로 훈련된다. T는 번역된 정답 시퀀스이고, S는 입력 시퀀스(Source)이며, S'는 Training set이다.
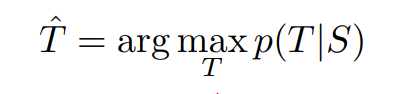
훈련이 끝나면, 가장 가능성이 높은 T를 찾아서 출력한다.
논문 저자들은 left-to-right beam search decoder를 사용했다고 한다. 이는 번역의 앞부분이 되는 "부분 가정(parital hypotheses)"을 B만큼의 적은 수로 유지하는데, 각 timestep마다 beam 안의 이 부분 가정을 점차 확장해나간다. 계속 확장하면 그 수가 기하급수적으로 늘어나므로, log likelihood에 따라 가장 높은 B개의 부분 가정만 남기고 나머지는 버린다. 이후 <EOS>를 만나게 되면 이 부분 가정을 beam에서 Complete Hypotheses로 옮긴다. 이런 방식으로 번역문을 생성하는 것이다.
5. Train
4개의 layer로 구성된 LSTM을 사용했으며, 각 layer는 1000 cell로 이루어졌고 word embedding은 1000 차원으로 이루어졌다. 입력 사전의 단어는 160,000개이고 출력 사전의 단어는 80,000개이다. 따라서 LSTM은 8000개의 실수를 사용하여 문장을 나타낸다. 그리고 naive softmax를 사용하여 80,000개의 단어에 대한 확률분포를 만든다. 최종적으로 LSTM은 384M개의 파라미터가 존재하게 된다.
LSTM의 파라미터들은 [-0.08, 0.08] 에서의 균등분포에 따라 초기화되었다. 또한, LSTM은 기울기 소실 문제가 적지만 기울기 폭주 문제가 존재한다. 따라서 norm이 일정 값을 넘었을 때, 이를 스케일링 해주는 것으로 제약을 걸었다. 각 훈련 배치마다 gradient의 크기를 구한 뒤, 이 크기가 5를 초과한다면 5*gradient / (gradient 크기)로 gradient 벡터를 나눠준다. 또한, 데이터셋에서 짧은 문장은 많지만 긴 문장은 적은 문제가 있다. 이로 인해 각 minibatch마다 많은 양의 계산 낭비가 발생한다. 이를 해결하고자 minbatch 안의 모든 문장들이 어느 정도 비슷한 길이의 문장들로만 구성되도록 설정하였다.
6. 병렬화
하나의 GPU만으로 학습하기에는 시간이 너무 오래 걸리기 때문에 8개의 GPU를 사용했다. LSTM의각 layer는 서로 다른 GPU에서 학습되고, 결과를 다음 GPU에 보내준다. LSTM은 4개의 layer로 구성되기 때문에 각 layer마다 하나의 GPU를 사용한다면 4개의 GPU가 남게 되는데, 이 4개의 GPU는 softmax 계산에 사용된다.
리뷰
LSTM을 먼저 읽지 않은 것이 아쉬웠다. 빠른 시일 내로 LSTM을 읽고 다시 살펴봐야겠다. 또한 beam search가 무엇인지에 대해서도 공부할 필요가 있을 것 같다. 한 가지 의문은 Sequence를 inverse 해서 minimum time lag이 줄어든건 알겠지만, 동시에 maximum time lag가 늘어났다. 이로 인해 "establishing communication"에서 어느 정도 문제가 발생할 수 있지 않을까? 그리고 이 문제로 인해 minimum time lag이 감소한 장점이 상쇄될 수도 있지 않을까 하는 의문이 생긴다.
출처
https://arxiv.org/abs/1409.3215
Sequence to Sequence Learning with Neural Networks
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this pap
arxiv.org
'논문 리뷰 > NLP' 카테고리의 다른 글
| [논문 리뷰] GPT-1 리뷰 (0) | 2022.10.14 |
|---|---|
| [논문 리뷰] GPT-1 : Improving Language Understanding by Generative Pre-Training (OpenAI) (2) | 2022.03.06 |

