
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- GPT
- 백준
- 논문
- 백준 1339 자바
- 논문구현
- 딥러닝
- 1107번
- 백준9095
- 백준 1916 자바
- 알고리즘
- 1916
- NLP
- 관심사분리
- Java
- 자바
- 짝지어제거하기
- 디미터법칙
- dijkstra
- 백준 1339
- deeplearning
- 1261
- 3745
- cs231n
- 다익스트라
- 머신러닝
- MachineLearning
- Alexnet
- 클린코드
- 알렉스넷
- 논문리뷰
- Today
- Total
산 넘어 산 개발일지
[논문 구현] VGG19(ICLR 2015) 구현 본문
2021.09.06 - [논문 리뷰/CV] - [논문 리뷰] VGG16(ICLR 2015) 요약 및 리뷰
[논문 리뷰] VGG16(ICLR 2015) 요약 및 리뷰
서론 1. 배경 Convolutional networks(ConvNets)는 대용량 이미지 및 영상 인식에서 큰 발전을 이룩하였는데, 이는 ImageNet과 같은 대용량 공공 이미지 데이터셋이 가능해지고, GPU와 같은 고성능 컴퓨팅 시
mountain96.tistory.com
1. Dataset
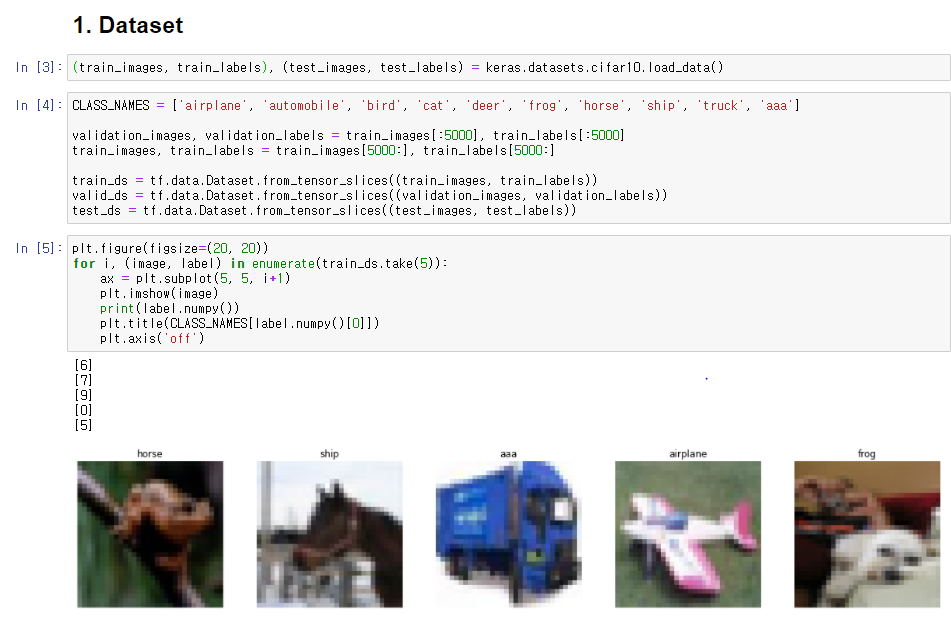
데이터셋은 CIFAR-10을 사용한다.
CIFAR-10은 총 60,000장(50000 train, 10000 test)의 데이터셋이 있으며, 각 이미지는 32x32사이즈이다.
train set 중 5000장은 validation set으로 활용한다.
그리고 이를 Tensorflow가 사용하기 용이한 Dataset으로 변환해준다.
2. Data/Input pipeline
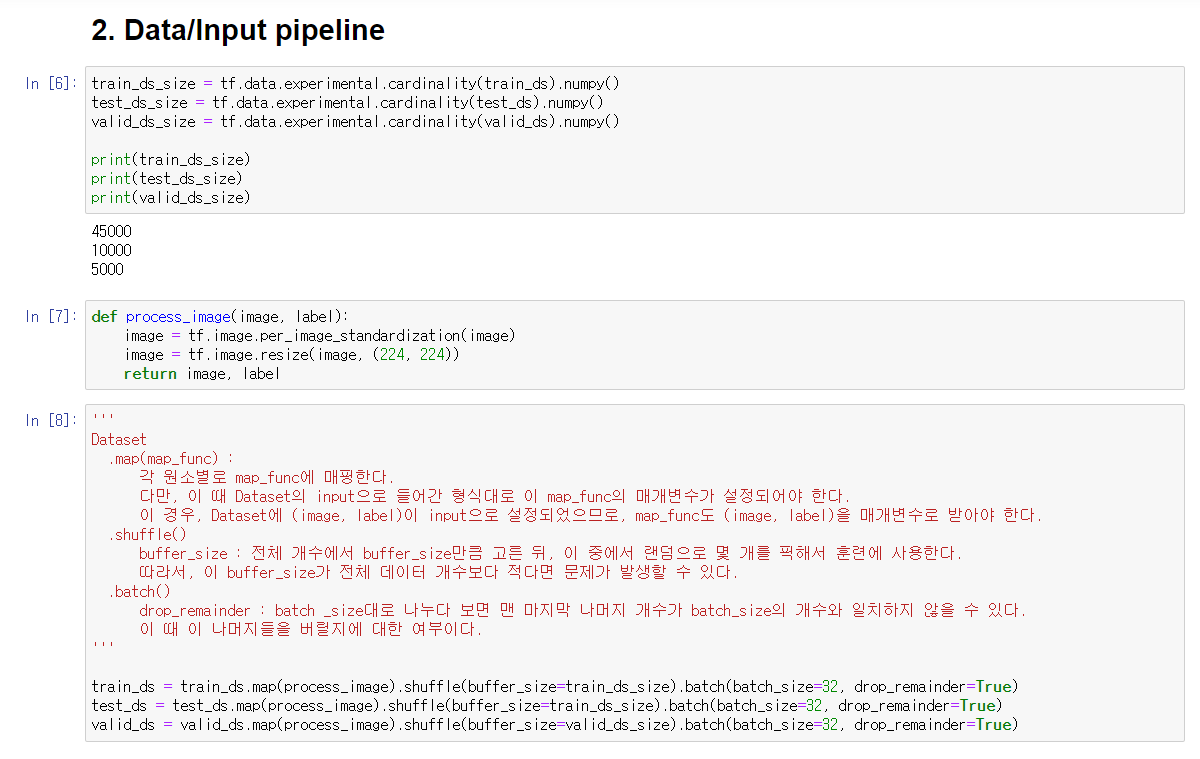
이후 각 Dataset이 사용될 때 이미지 전처리, shuffle, batch를 사용할 수 있도록 세팅한다.
2-1. 이미지 전처리
이미지 전처리는 standardization과 resize를 진행한다.
이 때 .map(map_function)을 사용하는데, 각 이미지별로 매핑될 함수를 지정하는 함수이다. 이 때 들어가는 함수의 매개변수는 Dataset을 생성할때 입력한 매개변수와 같다(이 경우 image, label)
standardization : 이미지의 픽셀값들이 평균 0, 분산 1 범위로 정규화한다.
resize : 32x32x3의 이미지를 VGG에 맞게 224x224x3의 이미지로 변환한다.
2-2. shuffle
매 훈련시마다 이미지들을 섞어준다.
.shuffle()함수를 사용하는데, 이 때 buffer_size를 해당 Dataset크기로 지정해줄 필요가 있다.
buffer_size는 전체 개수에서 buffer_size만큼만 고른 뒤, 이 중에서 랜덤으로 몇 개를 지정해서 훈련에 사용하는 것이다. 그렇기 때문에 이 값이 Dataset의 크기보다 작다면, 그 훈련에 사용되지 않는 이미지가 존재하게 된다.
2-3. batch
말 그대로 batch를 어떻게 나눌지를 지정한다.
batch_size로 size를 지정할 수 있으며, drop_remainder는 Dataset을 batch_size만큼 나누다 보면 마지막에 batch_size보다 적은 개수의 데이터들이 남게 될 텐데, 이들을 어떻게 처리할지에 대한 매개변수이다. 만약 True를 준다면 나머지 데이터들은 버린다.
3. Model Build

Model 구성은 위와 같다.(자세한 내용은 논문리뷰 참조)
이 때 Conv2D를 쌓을 때 stride와 activation을 지정하지 않아서 애먹었다.
Keras의 Conv2D는 stride를 지정하지 않으면 디폴트 (1,1)이 설정된다.
activation은 지정하지 않으면 활성화함수가 없이 None이 설정된다.
그렇기 때문에 activation만큼은 절대 잊지 말고 지정해줘야 한다.
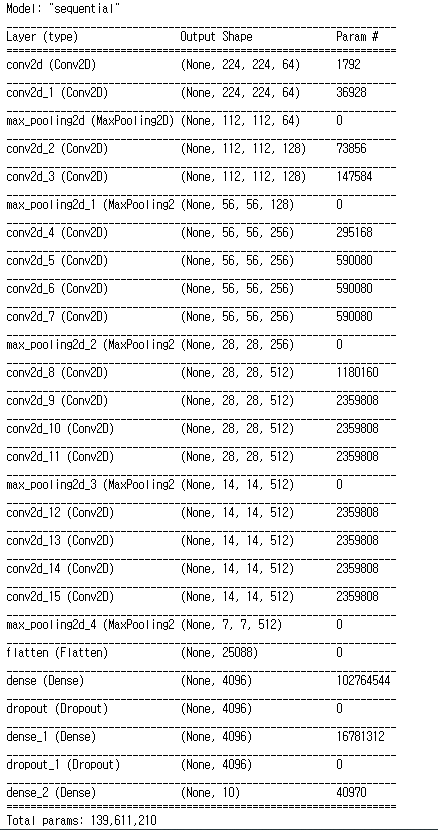
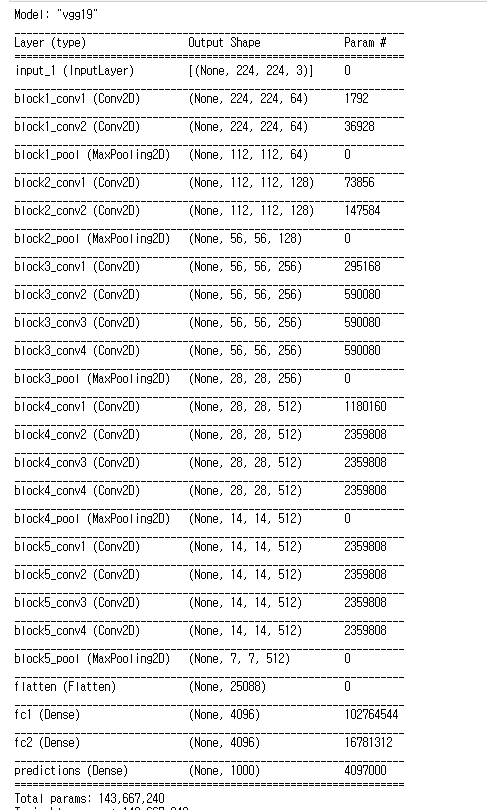
위 그림들은 내가 작성한 VGG19와 Keras에서 불러온 VGG19를 비교한 것이다.
파라미터 개수의 차이는 마지막 Prediction Layer에서 10과 1000개의 차이일 뿐, 만약 똑같이 1000으로 설정하면 파라미터 개수가 동일하다는 것을 확인하였다.
한 가지 의문이 들었던 것은, Keras에서는 FC layer 다음에 Dropout이 명시되지 않았던 점이다. 이 때문에 다시 논문을 뒤져봤으나, 역시 처음 두 개의 FC Layer 다음에 0.5 비율로 Dropout을 적용했다고 나와 있었다. Keras에서는 Functional API를 사용했는데, 이 때문에 Dropout이 명시되지 않은 건지도 모르겠다.(실제로, Keras에서 로드한 모델의 첫 부분에는 InputLayer가 존재하지만 Sequential로 모델을 쌓을 때는 InputLayer를 입력해도 summary()에서는 명시되지 않았었다.)
4. Model Fit
결과를 모니터링할 수 있게 callbacks.TensorBoard를 사용했다.
논문에서는 validation_accuracy가 증가하지 않으면 learning rate를 0.1배 시켰다고 나왔다. 나같은 경우는 2 에포크동안 증가하지 않으면 0.1배 시키도록 설정했다.
또한 논문에서와 마찬가지로 momentum=0.9를 준 SGD를 사용했다.
결과는 다음과 같다.
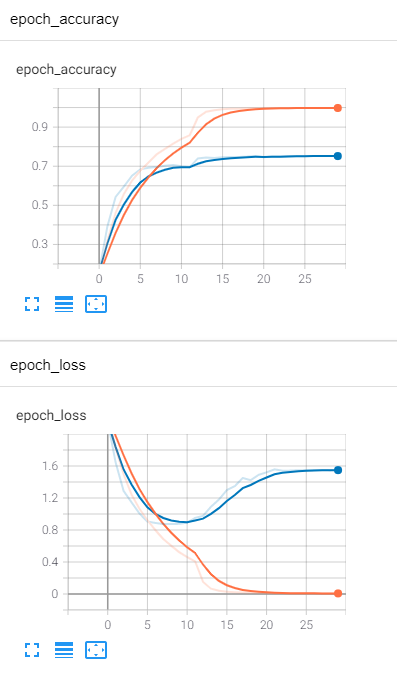
마지막 Validation Accuracy는 0.7을 조금 넘은 상태로 수렴했다. 그러나 Loss를 보면 10 에포크부터 Overfitting이 일어났음을 알 수 있다. 왜 Overfitting이 일어났을지 생각해봤는데, 아무래도 이미지 사이즈를 억지로 늘린 것에서 큰 영향이 있지 않을까 싶다. 애초에 32x32 사이즈의 이미지이고, 여기에 적용하기에 VGG19는 너무 깊은 모델이기 때문이다. 이를 224x224로 늘린다 하여도 유용한 데이터가 증가하지는 않았을 것이다. 네트워크의 깊이를 조금 더 줄인다면 보다 괜찮은 정확도 나올 것으로 예상한다.
Reference
'논문 리뷰 > CV' 카테고리의 다른 글
| [논문 리뷰] VGG16(ICLR 2015) 요약 및 리뷰 (0) | 2021.09.06 |
|---|---|
| [논문 구현] AlexNet(2012) 구현 (2) | 2021.08.10 |
| [논문 리뷰] AlexNet(2012) 요약 및 리뷰 (0) | 2021.08.05 |


